 17.07.2017
17.07.2017ԲԱՌԵՐԻ ՏԻԵԶԵՐՔ. ՀԱՃԱԽԱԿԻՈՒԹՅԱՆ ԲԱՌԱՐԱՆՆԵՐԸ ԵՎ GOOGLE N-GRAMS ԳՈՐԾԻՔԸ
![]()
![]()
Արա Հ. Մարջանյան
ՄԱԿ ԶԾ էներգետիկայի ազգային փորձագետ, տ.գ.թ., «Նորավանք» ԳԿՀ ավագ փորձագետ
Հոդվածը հիմնված է 2011թ. համանուն ակնարկի վրա, որը 2016թ. նոյեմբերի 18-ին ներկայացվեց «Նորավանք» ԳԿՀ կոնտենտ անալիզի սեմինարին: Հեղինակը շոյված է, որ «Dasaran.am» կայքում 2014-ից մեկնարկած հայերեն բառապաշարի հարստացմանն ուղղված խաղը կոչվում է «Բառերի տիեզերք»:
Ալեքսանդր (Ալիս) Մարջանյանի հիշատակին
En archē ēn ho Lógos, kaì ho Lógos ēn pròs tòn Theón, kaì Theòs ēn ho Lógos.
Սկզբից էր Բանը, եւ Բանը Աստծու մօտ էր, եւ Բանը Աստուած էր։
In principio erat Verbum, et Verbum erat apud Deum, et Deus erat Verbum.
In the beginning was the Word, and the Word was with God, and the Word was God.
Au commencement était la Parole, et la Parole était avec Dieu, et la Parole était Dieu.
В начале было Слово, и Слово было у Бога, и Слово было Бог.
Յովհաննէս, 1.1.
1. Նախաբան
Արևմտյան կիսագնդում բառերի մասին խոսելիս գրեթե անհնար է սկսել առանց Հովհաննեսի Ավետարանի առաջին տողը ցիտելու1։ Այսպես ենք վարվում և մենք՝ բնաբանում բերելով ոչ միայն այդ տողի հունարեն բնագիրը, այլև դրա հայերեն, լատիներեն, անգլերեն, ֆրանսերեն և ռուսերեն կանոնակարգային թարգմանությունները: Անում ենք դա՝ ընդգծելու համար հետևյալ բազմանշանակ փաստը. հունարեն բնագրի լոգոսը, հուրախություն Հերակլիտեսի, մեր հայրերը թարգմանել են որպես բան, այլ ոչ թե բառ կամ խոսք: Ինչպես որ դա արված է բազմաթիվ այլ լեզուներում2։
Բանն այն է, որ ի սկզբանե հայերեն լեզվամտածողությունում բան բառը չափազանց բազմիմաստ էր: Եվ այն լիովին պահպանել է իր ողջ բազմիմաստությունը մինչ օրս՝ նշանակելով և՛ խոսք, և՛ բառ, և՛ իր, և՛ գործ: Կարճ ասած՝ հայերենը պահպանել է մարդկության հինավուրց գաղտնիքը՝ բառը դառնում է բան, գործ և իրականություն: Եվ հակառակը՝ բանը, իրականությունը դառնում են բառ և խոսք: Համաձայն Հր.Աճառյանի, Բառ և Բան բառերը գոյացել են բուն հայերեն Բալ բայից ([1], հ.1, էջ 383, 403, 413): Պարզ արմատն է բնաձայն Բա-ն՝ խոսել, բարբաջել, բլբլալ իմաստով: Այս բայից են ավանդված եզակի երեք դեմքերը՝ Բամ, Բաս, Բա, որոնք ներկայում անկախ չեն գործածվում: Թեև ունենք Բամբասանք բառը, ինչպես նաև Բա և Բաս բառերը՝ հաստատում արտահայտելու համար: Օրինակ՝ «Բա որ ասում էի»: Ավագ գործընկերներս կհիշեն. 1964թ. հոկտեմբերին պաշտոնանկ արվեց ԽՄԿԿ Կենտկոմի առաջին քարտուղար, ԽՍՀՄ Մինիստրների խորհրդի նախագահ Ն.Ս. Խրուշչովը: Նրանք հավանաբար կհիշեն նաև, որ, համաձայն այդ ժամանակվա «Հայկական ռադիո»-ի, այս կապակցությամբ Խրուշչովին հղված ամենակարճ հեռագիրը Լենինականից էր: Այն կազմված էր միայն մեկ բառից՝ «Հբը՛»:
Պահանջվեցին ԽՍՀՄ փլուզումը 1991-ին և ԱՄՆ-ում տեղեկատվության ազատության մասին օրենքի (FOIA) ընդունումը՝ 1997-ին, որպեսզի մեզ հայտնի դառնա այն ուշիմությունը, որով ԱՄՆ ԿՀՎ-ն հետևում ու վերլուծում էր «Հայկական ռադիո»-ի կատակները, այդ թվում և վերը բերվածը: Ցավոք, համանման օրենք չընդունվեց ոչ ԽՍՀՄ-ում ու ՌԴ-ում, ոչ էլ Հայաստանում, և մենք այդպես էլ չտեսանք այն փաստաթղթերը, որոնք ցույց կտային ՊԱԿ և ԽՄԿԿ ԿԿ գաղափարական բաժնի բանուկ գործունեությունը «Հայկական ռադիո»-ի որոշ կատակների ու տարատեսակ բամբասանքների տարածման գործում: Ասում ենք սա՝ ընդգծելու համար բազմաթիվ, հաճախ՝ անսպասելի կապերը, որոնք առկա են լեզվի ու լեզվամտածողության և քաղաքականության ու աշխարհաքաղաքականության միջև3։
2. Հաճախակիության բառարանները՝ մինչ 2010թ. դեկտեմբեր
Մարդկային տարատեսակ ձեռնարկումների շարքում բառարանների կազմումը, թերևս, ամենազարմանալին է: Իրոք, ինչպես կարելի է հուսալ տեղավորել բառերի ողջ բազմությունը մի գրքում4, որքան էլ մեծ ու ծավալուն լինի այն: Չէ՞ որ այն ծիծաղելիորեն վերջավոր է բառերի անծայրածիր ու հարափոփոխ օվկիանոսի համեմատ: Այնուամենայնիվ, ահա դրանք, գրված ամենատարբեր լեզուներով՝ բացատրական, ստուգաբանական, արմատական և բազում այլ բառարաններ: Նվիրված մարդկային գործունեության ամենատարբեր ոլորտներին՝ հեքիաթների սյուժեներից մինչև բանտային արգոյի բառարաններ, մարդկության սիմվոլներից և այլասերումներից մինչև ազգերի ժեստերի բառարաններ: Անգամ խորհրդավոր՝ թվերի բառարաններ:
Առանց այդ էլ տարօրինակ այս աշխարհում կա նույնիսկ ավելի զարմանալի մի բան: Խոսքս բառերի հաճախակիության բառարանների մասին է: Դրանք ցույց են տալիս, թե տվյալ լեզուն կիրառող մարդիկ որքան հաճախ են օգտագործում այս կամ այն բառը (վանկը կամ բառակապակցությունը) խոսակցական կամ տպագիր լեզվում: Կրկնակի դժվար մի բան, քանի որ այսպիսի բառարանը գործ ունի միաժամանակ երկու (համարյա) անվերջությունների հետ. նախ՝ հենց բուն բառերի տիեզերքի, իսկ այնուհետև՝ այդ տիեզերքը կազմող յուրաքանչյուր բառի, ավելին՝ բառակապակցությունների օգտագործման քանակական ասպեկտների հետ: Զարմանալի չէ, որ հաճախակիության բառարաններն ի հայտ են գալիս միայն XIX դարի վերջին, երբ մարդկությունը դառնում է բավարար հասուն այսպիսի ձեռնարկման համար: Երբ կապիտալիզմը թևակոխում էր իմպերիալիզմի դարաշրջանը, մարդկությունն ինքնավստահ էր ու գործունյա, իսկ աշխատանքի արդյունավետ կազմակերպման և վիճակագրա-հաշվողական մեթոդները հասան նախկինում նախադեպը չունեցող մակարդակի:
Ինչպես և գրեթե միշտ նորագույն պատմությունում, առաջինը գերմանացիներն էին: Խոսքս ժամանակին լեգենդար, իսկ այսօր՝ հիմնովին մոռացված Ֆ.Վ. Քայդինգի մասին է (Kaeding), որը 1891-ից գերմանական Ռայխի տարբեր վայրերում իր մոտ 100 բյուրոներում աշխատեցնելով մինչև 5000 հոգի՝ 6 տարում կազմեց և 1897/98-ին հրատարակեց գերմաներենի հաճախակիության իր մոնումենտալ բառարանը [3]: Այն ներառում էր մոտ 20 մլն վանկերի ու հնչյունների և մոտ 11 մլն բառօգտագործման բազմություն (կորպուս՝ ինչպես ասում են լեզվաբանները): Այն վերցված էր ավելի քան 300 գրավոր և բազմաթիվ բանավոր լեզվական աղբյուրներից: Առաջին այս մոնումենտալ փորձը տևական ժամանակ մնաց անգերազանցելի: Հետաքրքրական է, որ XX դարի առաջին կեսին առավել պահանջված էին Քայդինգի ոչ թե զուտ լեզվաբանական արդյունքները, այլ նրա աշխատանքի կազմակերպման փորձը: Այն մանրակրկիտ ուսումնասիրվեց Մեծ Բրիտանիայում, Ֆրանսիայում և ԱՄՆ-ում, օգտագործվեց այդ երկրների վիճակագրական բյուրոների աշխատանքների կազմակերպման համար, ներդրվեց մի շարք խոշոր կորպորացիաներում (Hughes Aircraft Cօ, IBM, և այլն) ու նույնիսկ օգտագործվեց ԱՄՆ և ՄԲ ատոմային զենքի ստեղծման ծրագրերում:
Լեզվական առումով Քայդինգի արդյունքներն օգնեցին ձևակերպել լեզվի վիճակագրական և հաճախակիության մի շարք կարևոր հասկացություններ (Ցիպֆի օրենք, Ցիպֆ-Մանդելբրոթի սկզբունք, Պարետոյի սկզբունք, Սվոդեշի ցուցակներ և այլն). զուտ լեզվաբանական, համեմատական լեզվաբանության, լեզվի և քերականության էվոլյուցիային նվիրված ուսումնասիրություններում ներմուծել քանակական գնահատականներ, ինչը հող նախապատրաստեց ապագայի «կորպուսային լեզվաբանության» համար (տես՛ ստորև): Քայդինգի արդյունքներն օգնեցին ձևակերպել նաև տեքստերի (հիմնականում՝ անգլերեն) ընթեռնելիության (Ռ.Ֆլեշ) և ընկալունակության (Ֆլեշ-Քինքեյդի թեստ և այլն) չափանիշները, ցույց տալ եզրերի (տերմինների) օգտագործման դյուրինության, տարածվածության և օգտագործման հաճախակիության կապը տվյալ եզրի կարճության հետ: Մի փոքր շեղվելով շարադրանքից՝ դիտարկենք հարցն ավելի հանգամանալի և սկսենք ուշագրավ մի փաստից:
FOIA շրջանակներում հասանելի են աղբյուրներ, որոնցում, հիմնված Երկրորդ աշխարհամարտի փորձի վրա, իրականացվում է մարտի դաշտում օգտագործվող ճապոներեն և անգլերեն հրամանների ու արտահայտությունների համեմատական վերլուծությունը: Եզրակացությունը՝ անգլերեն հրամանների և եզրերի կարճությունը, ի շարս այլ գործոնների, խթանում էր մարտի դաշտում ավելի նախաձեռնող և արդյունավետ վարքը: Անգլերենի և անգլերեն եզրերի տարածվածությունն աշխարհում ունի, անշուշտ, շատ պատճառներ՝ գաղափարախոսական, տեխնոլոգիական, սոցիալական, լեզվահոգեբանական ու պատմական: Սակայն կարևոր նշանակություն ունեն նաև անգլերենի հակիրճությունը և անգլերեն եզրերի կարճությունը:
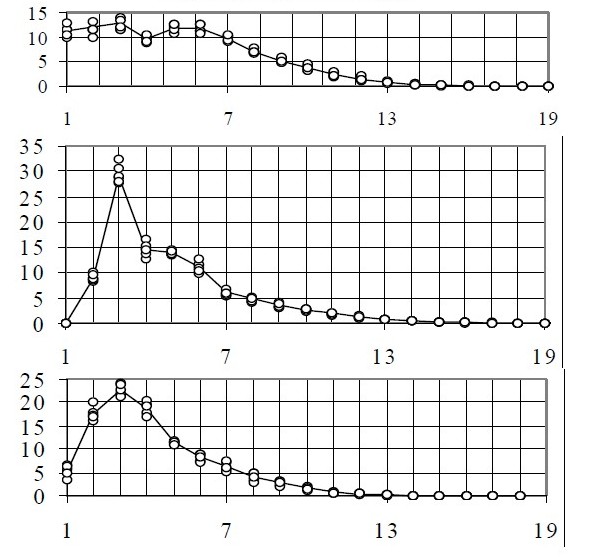
Նկար 1. Ռուսերեն (վերևում), գերմաներեն (մեջտեղում) և անգլերեն (ներքևում) տեքստերում բառերի հաճախակիության (%) կախվածությունը բառերի երկարությունից (հատ տառ) [4]:
Նկար 1-ում բերում ենք սովորական, ոչ տեխնիկական, ռուսերեն, գերմաներեն և անգլերեն տեքստերում բառերի հաճախակիության (%, Y-երի առանցք) կախվածությունը դրանց երկարությունից, այսինքն` նրանցում տառերի քանակից (X-երի առանցք) [4]: Ինչպես տեսնում ենք, ռուսերենում եռատառ բառերի հաճախակիությունն ունի այդ լեզվին բնորոշ մինիմում: 4 ու 5 տառ երկարությամբ բառերի համար հաճախակիությունը գրեթե հավասար է միմյանց (մոտ 12% յուրաքանչյուրը), իսկ 6 տառից հետո այն մոնոտոն նվազում է: Ընդհանուր առմամբ, ռուսերենի հաճախակիության կորն ունի 2 մաքսիմումի և 3 շրջման կետ (inflection point): Ռուսերեն բառերի միջին երկարությունը կազմել է 5.13 բառ: Իսկ կարճ՝ մինչև 4 տառ երկարությամբ, բառերը կազմում են սովորական ռուսերեն տեքստի մոտ 45%-ը: Գերմաներեն բառերի միջին երկարությունը կազմել է 5.07 բառ, իսկ հաճախակիության կորն ունի երկու շրջման կետ: Հակառակ ռուսերենի, այստեղ նկատելի է եռատառ բառերի հաճախակիության պիկ՝ մոտ 30%: Ինչպես և ռուսերենում, 4 ու 5 տառ երկարությամբ բառերի հաճախակիությունը գրեթե հավասար է: Բայց այն ավելին է, քան ռուսերենում (մոտ 15%): Ադրյունքում՝ գերմաներենում կարճ բառերը նույնպես կազմում են տեքստի մոտ 45%-ը:
Միանգամայն այլ է պատկերն անգլերենում: Այստեղ հաճախակիության կորը ողորկ է ու չի տարբերվում դասական, երկպարամետր ասիմետրիկ բաշխման կորից (Վեյբուլի բաշխում), որը բնորոշ է բնական ամենատարբեր երևույթներին:5 Այն ունի միայն մեկ պիկ՝ եռատար բառերի համար, որին հետևում է մոնոտոն անկում՝ շրջման միայն մեկ կետով (տես՛ Նկ. 1): Անգլերեն բառերի միջին երկարությունը կազմել է 4.24 բառ, այսինքն՝ 19.6% և 21%-ով ավելի քիչ, քան գերմաներենում և ռուսերենում համապատասխանաբար: Իսկ ամենակարևորն այն է, որ անգլերենում կարճ՝ մինչև 4 տառ երկարությամբ, բառերը կազմում են սովորական տեքստի կեսից ավելին՝ 67%-ը: Այսինքն՝ մոտ 22% ավելին, քան գերմաներենում և ռուսերենում: Հետևաբար, սովորական անգլերեն տեքստը առնվազն 22%-ով ավելի կարճ է գերմաներենից և ռուսերենից: Ի դեպ, ցիտվող ուսումնասիրությունում այս եզրահանգումը զարմանալիորեն բացակայում է:
Բերենք մի խոսուն փաստ ևս՝ ծովակալ Ջ.Ֆիշերի հայտնի «hit first, hit hard, keep hitting» ասույթի օրինակով: Ինչպես տեսնում ենք, այն պարունակում է 26 տառ, չհաշված ստորակետները: Ռուսերեն թարգմանությունը՝ «Бей первым, бей сильно, продолжай бить», պարունակում է 31 տառ՝ բնագրից մոտ 20% ավելի: Դե, իսկ հայերենը՝ «Հարվածիր առաջինը, հարվածիր ուժեղ, շարունակիր հարվածել»` 44 տառ, բնագրից գրեթե 40% ավելի: Անգլոսաքսոնյան աշխարհաքաղաքականության այս հակիրճ բանաձևը բնութագրում է ոչ միայն XIX-XXI դարերի բրիտանա-ամերիկյան ծովային էքսպանսիան, այլև աշխարհում անգլերեն տեխնիկական եզրերի ներկայիս լայն տարածումը:
Բանն այն է, որ սովորական անգլերենի հակիրճությունն էլ ավելի բնորոշ է անգլերեն տեխնիկական և բնագիտական լեզվին: Անգլերեն եզրերի կարճությունը, դրանց օգտագործման դյուրինությունը, կրկնենք՝ ի շարս այլ կարևոր գործոնների, ապահովում են դրանց համատարած գործածությունն ու տարածումն աշխարհում: Հակառակը, hայերեն մասնագիտական լեզվօգտագործման ներկայիս անմխիթար վիճակը, ի շարս այլ գործոնների, պայմանավորված է նաև հայալեզու տեխնիկական և գիտական եզրերի ներկա անճոռնի ձևով, դրանց անբնական, հաճախ՝ արհեստածին երկարությամբ ու ապակողմնորոշող բնույթով:
Վերադառնանք, սակայն, հաճախակիության բառարաններին: XX դարի 2-րդ կեսի գլոբալ հակամարտության և Սառը պատերազմի իրողությունները պայմանավորեցին հեռահաղորդակցության, հաշվիչ տեխնիկայի, կոդավորման, գաղտնավերլուծության (cryptanalysis) աննախադեպ զարգացումը՝ շեշտակի բարձրացնելով լեզվի հաճախակիության հարցերի նկատմամբ ուշադրությունը: 50-70-ականների ընթացքում կազմվեցին անգլերեն, իսպաներեն, ֆրանսերեն, գերմաներեն, պորտուգալերեն, ճապոներեն և իտալերեն լեզուների հաճախակիության առաջին բառարանները: Ուշագրավ է, որ ռուսերեն լեզվի առաջին այդպիսի բառարանը կազմվեց 1952-53-ին ԱՄՆ-ում [6]6, իսկ ԽՍՀՄ-ում առաջինը հրատարակվեց միայն 10 տարի անց [8]: 1.0 մլն բառօգտագործման կորպուսի վրա հիմնված ռուսերենի առաջին հաճախային բառարանը հրատարակվեց միայն 1977-ին [9], այն դիտարկում էր մոտ 39 հազ. բառ: Հայոց լեզվի հաճախակիության բառարանի կազմման հարցն առաջին անգամ դրվեց դեռ 1967-68թթ. Բ.Կ. Ղազարյանի կողմից [10]: Իսկ 1982-ին հրատարակվեց նրա «Ժամանակակից հայոց լեզվի հաճախականության7 բառարանը» [11], որը բերում էր մոտ 36 հազ. բառ:
Փաստենք հետևյալը. չնայած բազմաթիվ խոչընդոտներին ու դժվարություններին, այս առումով 60-70-ական թթ. ՀԽՍՀ-ն գրեթե չէր զիջում միջազգային միտումներին, համահունչ էր դրանց, եթե ոչ որակական, ապա գոնե քանակական առումներով: Մինչդեռ, անցած 25 տարիների ընթացքում Հայաստանի 3-րդ Հանրապետությունում չի իրականացվել արդի հայերենի բառօգտագործման հաճախակիության ասպեկտների որևէ համալիր ուսումնասիրություն: Չեն մշակվել հայերեն բնագիտական և տեխնիկական եզրերի օգտագործման դյուրինության և յուրացման չափանիշները: Չի ուսումնասիրվել եզրերի օգտագործման հաճախակիության կախվածությունը դրանց երկարությունից: Չեն նկարագրվել այս կախվածության առանձնահատկություններն ըստ կիրառման տարբեր ոլորտների և այլն: Այսօր Նկ.1-ում մենք նույնիսկ չենք կարող հայերենի կորն ավելացնել: Քայդինգի և Ցիպֆի աշխատություններից մեկ դար անց այն դեռևս կառուցված չէ: Մնում է միայն ափսոսել, որ դեռ XX դարի 70-ականների սկզբին Ա.Մ. Մարջանյանի նախաձեռությունը՝ կազմել և հրատարակել հայերեն տեխնիկական կարճ եզրերի բառարան, մնաց անավարտ՝ հանդիպելով բազում արգելքների:
3. Կորպուսային լեզվաբանություն
Մինչ 2010թ. կազմված հաճախակիության բոլոր բառարաններին բնորոշ էին էական սահմանափակումներ: Պարզաբանենք դրանք [9]-ի օրինակով: Այս բառարանը բերում է 39 268 առանձին բառերի և նշանակություն ունեցող մասնիկների օգտագործման հաճախակիության նկարագիրը՝ հիմնված մոտ 1.1 մլն միավոր բառօգտագործման կորպուսի վրա: Կորպուսը կազմված էր ռուսալեզու 13 հրապարախոսական, 11 գեղարվեստական, 1952-1966թթ. ընթացքում հրապարակված 14 դրամատիկ ստեղծագործությունների, ինչպես նաև 1968թ. հունվարի 5-ին լույս տեսած մի շարք թերթերի (Водный транспорт, Известия, Комсомольская Правда, Правда, Труд և այլն) տեքստերից8։
Առավելագույն հաճախակիությունը փաստված է «в(во)» մասնիկի համար՝ 42854 անգամ (մոտ 4x10-2%): «Если» բառն օգտագործված է 1929 անգամ (մոտ 1.8x10-3%): Ընդ որում, գեղարվեստական և դրամատիկ աղբյուրներում այն օգտագործվել է շոշափելիորեն ավելի հաճախ, քան հրապարակախոսական աղբյուրներում և մամուլում: «Хаос» բառն օգտագործված է ընդամենը 18 անգամ: Մինչդեռ «космос» բառը՝ 35 անգամ, իսկ «космический» բառը՝ 114 անգամ: Ազգային-աշխարհագրական երանգ ունեցող առավել հաճախ օգտագործվող բառերի ցանկում առաջինը «Советский» բառն է (1137 անգամ), որին հաջորդում են «американский» (618 անգամ) և «русский» (514 անգամ) բառերը: Այս ցանկում են նաև «украинский» (24 անգամ), «армянский» (19 անգամ), «белорусский» (13 անգամ), «грузинский» (11 անգամ) բառերը: Բառարանում հատկանշականորեն բացակայում է «геноцид» բառը9։ Ընդհանրապես, 10 և ավելի անգամ օգտագործված բառերի ընդհանուր քանակը կազմում է 9044 միավոր, այսինքն՝ բոլոր դիտարկված բառերի 23%-ը: Բայց դրանք կազմում են դիտարկված 1.1 մլն միավոր բառօգտագործման կորպուսի ծավալի 92.4%-ը:
Այսպիսով, [9] բառարանը տալիս է, այսպես ասած՝ «միջին կշռված» ռուսերեն լեզվի հաճախակիության հատույթը, այն էլ միայն XX դարի մոտավորապես 60-ականների կեսերի դրությամբ: Հասկանալի է, որ [9]-ի արդյունքների համարժեքությունն ամբողջապես պայմանավորված է բառօգտագործման կորպուսի «ռեպրեզենտատիվությամբ»: Այսինքն՝ հեղինակների կողմից տեքստերի աղբյուրների կատարված ընտրությամբ, լեզվի նկատմամբ նրանց զգայունությամբ ու տակտով: Այս առումով կորպուսն անխուսափելիորեն սուբյեկտիվ է, ենթակա տվյալ ժամանակին բնորոշ գաղափարախոսական, քարոզչական ներազդմանը և հեղինակների անձնական նախապաշարումներին: Բացի այդ, կորպուսը ստատիկ է՝ կապված օգտագործված աղբյուրների տպագրման ժամանակային բավական նեղ սփռվածության հետ: Հետևաբար, այն ունակ չէ նկարագրել տվյալ բառի օգտագործման հաճախակիության փոփոխությունը քիչ թե շատ տևական ժամանակի ընթացքում: Հաջորդը. կորպուսը դիտարկում էր հիմնականում միայն մեկ բառ (կամ մասնիկ)՝ մթության մեջ թողնելով այս կամ այն բառակապակցության (քերականական արտահայտության) օգտագործման հաճախակիության հարցը: Վերջապես, կորպուսը և նրա մետադատան դժվարահաս էին հետագա ընդլայնման ու վերլուծությունների համար: Դրանք հանրայնացված չէին, իսկ հետազոտությունների արդյունքների վիզուալիզացիայի հնարավորությունները խիստ սահմանափակ էին: Այս ամենը, իհարկե, վերաբերում է ոչ միայն [9]-ին, այլև մինչ 2010թ. դեկտեմբեր բոլոր լեզուներով հրատարակված հաճախակիության բոլոր բառարաններին:
Նշված սահմանափակումները մասնակիորեն հաղթահարվեցին 1985-2000-ականներին, մի շարք լեզուների ազգային կորպուսների ստեղծման ընթացքում: Հաշվիչ տեխնիկայի զարգացումը, համացանցի ստեղծումն ու տարածումը մեծապես օժանդակեցին այս գործընթացին: Այդ ժամանակ ստեղծված լեզվի ազգային կորպուսները նախորդներից ավելի ծավալուն էին՝ 1.0-5.0 մլն բառօգտագործում: Ունեին ավելի տարբերակված ու հատուկ բնույթ, օրինակ՝ ավստրալերեն կամ բրիտանական անգլերենի կորպուսներ, խոսակցական լեզվի կորպուսներ և այլն: Դրանք հիմնվում էին ժամանակի մեջ ավելի սփռված աղբյուրների վրա՝ մինչև մի քանի տասնյակ տարի: Իսկ նոր լավագույն կորպուսների յուրաքանչյուր միավոր արդեն ուներ իրեն բնորոշ թագերի10 (tag) բազմություն և զարգացած մետադատա, ինչը հնարավոր էր դարձնում կորպուսներում այս կամ այն չափանիշով որոնումների, զտումների, ներքին խմբավորումների կազմակերպումը, ինչն, իր հերթին, շոշափելիորեն ընդլայնում է ուսումնասիրությունների տիրույթը և ճկունությունը: Որոշակիորեն դյուրինացավ նաև դրանց հասանելիությունը՝ այնուամենայնիվ մնալով սահմանափակ իրապես լայն լսարանի համար: Ըստ էության, լեզվի ազգային կորպուսները դարձան արդի իմաստով՝ տվյալների մեծ շտեմարաններ (Big data base): Այս ժամանակ թվայնացվեց դեռ 60-ականներին ստեղծված անգլերենի Բրաունի համալսարանի լեզվական կորպուսը (Brown Corpus): Ստեղծվեցին ավելի մեծ ու ստրուկտուրացված կորպուսներ՝ անգլերենի բանկը (Bank of English)՝ Բիրմինգհեմի համալսարանում, բրիտանական անգլերենի կորպուսը (BNC) և այլն: Կազմվեցին իսպաներենի, գերմաներենի և ֆրանսերենի ազգային կորպուսները: ԽՍՀՄ-ում այս մասշտաբի առաջին ձեռնարկումը ակադ. Ա.Պ.Երշովի կողմից 1983-85թթ. նախաձեռնված Ռուսերենի մեքենայական ֆոնդի (Машинный фонд русского языка, МФРЯ) ստեղծման ծրագիրն էր, որը ԽՍՀՄ փլուզման հետևանքով մնաց անավարտ: Աշխատանքները վերսկսվեցին միայն 2004-ից՝ Ռուսերենի ազգային կորպուսի (НКРЯ) ստեղծման ծրագրի շրջանակներում: Եվ սա զուտ պատահականություն չէ, որ ռուսերենի ազգային կորպուսի կազմման ծրագրի վերակենդանացումը զուգադիպում է ՌԴ-ի կողմից ինքնուրույն աշխարհաքաղաքականություն մշակելու և վարելու, պետական ու ազգային սուվերենության վերիմաստավորման նոր ժամանակաշրջանի հետ [12]: Դե, իսկ ինչ վերաբերում է Հայաստանին, ապա թե՛ ՀԽՍՀ-ն՝ իր գոյության վերջին տարիներին, թե՛ նորաստեղծ 3-րդ Հանրապետությունը՝ մի շարք օբյեկտիվ և սուբյեկտիվ պատճառներով, ամբողջությամբ դուրս մնացին 1985-2000-ականներին ծավալված այս գործընթացներից:
4. 2010թ. դեկտեմբերյան մեծ հեղափոխությունը
Ամեն ինչ փոխվեց 2010թ. դեկտեմբերի 16-ին, երբ Science պարբերականի ինտերնետ կայքում հայտնվեց «Կուլտուրայի11 քանակական վերլուծություն՝ հիմնված թվայնացված միլիոնավոր գրքերի վրա» հոդվածի ազդագիրը: Հոդվածն ամբողջությամբ տպագրվեց պարբերականի 2011թ. հունվարյան հատորում [13]: Հեղինակները՝ Հարվարդի համալսարանի էվոլյուցիոն դինամիկայի, մաթեմատիկայի, հոգեբանության և քանակական սոցիոլոգիայի ամբիոններից, Հարվարդի ճարտարագիտական և կիրառական գիտությունների դպրոցից, Մասաչուսեթսի տեխնոլոգիական ինստիտուտի արհեստական բանականության լաբորատորիայից, Բոստոնի բժշկական դպրոցից, Google Inc. և Encyclopaedia Britannica, Inc. ընկերություններից, ազդարարեցին մի քանի կարևորագույն բան:
Նախ, 2008թ. վերջին Google Books թիմի կողմից սքանավորվել է աշխարհի բոլոր գրադարաններում պահվող մոտ 129 մլն անուն գրքից մոտ 15 մլն-ը, տպագրված 1500-2008թթ. ժամանակահատվածում: Այսինքն՝ սքանավորվել է Գուտենբերգի տպագրության գյուտից մինչև 2008թ. աշխարհում երբևէ տպագրված գրքերի մոտ 12%-ը: Այս բազմությունից ընտրվել է 7 լեզվով մոտ 5.1 մլն գիրք՝ աշխարհում երբևէ տպագրված գրքերի մոտ 4.0%, որոնց սքանավորման որակը (optical character recognition) թույլ է տվել ամբողջությամբ թվայնացնել դրանք: Արդյունքում՝ կազմվել է դրանցում առկա բառօգտագործման կորպուսը, մոտ 500 մլրդ բառօգտագործման միավոր գլխապտույտ առաջացնող ծավալով:
Հասկանանք տեղի ունեցածը թվերով: Նախ՝ 4.0%-ը քի՞չ է, թե՞ շատ: Եթե հարցին մոտենանք առօրեական տրամաբանությամբ, դա առանձնապես տպավորիչ չէ: Դե, դժվար թե մենք գոհ լինեինք, եթե մեզ վերադարձնեին պարտքի միայն 4.0%-ը: Սակայն եթե գործին նայենք իրական բնագիտությանը բնորոշ ավելի խոնարհ տեսանկյունից, ապա դա այնքան էլ քիչ չէ: Իրոք, ներկայիս հպարտ ֆիզիկան պատկերացում ունի Տիեզերքի միայն 4%-ի մասին: Դա, այսպես կոչված` սովորական, բարիոնային նյութն է: Մնացյալը, այսինքն՝ Տիեզերքի 96%-ը, այսպես կոչված «մութ նյութն» է, որը տակավին անհայտ է այսօրվա գիտությանը12։ Այնպես որ, սա չափազանց տպավորիչ արդյունք է, համադրելի արդի բնագիտության հետ: Առավել ևս, եթե հիշենք, որ մինչև 2010թ. կազմված լեզվի լավագույն կորպուսները հիմնվում էին միայն մոտ մի երկու-երեք հարյուր անուն տպագիր աղբյուրների տեքստերի վրա: Այսինքն՝ երբևէ տպագրված գրքերի ընդամենը մոտ 0.0004%-ի վրա:
Տեղի ունեցածն էլ ավելի տպավորիչ է ուղիղ թվերով: Մինչ 2010թ. կազմված լեզվի լավագույն ազգային կորպուսների ծավալը չէր գերազանցում 5 մլն բառօգտագործումը՝ չհաշված Քայդինգի անգերազանցելի ռեկորդը: Այսինքն՝ մոտ հարյուր հազար անգամ փոքր, քան Google Books կորպուսի ծավալը: Այլ խոսքերով, Google Books կորպուսի ռեպրեզենտատիվությունը դրանց համեմատ աճել է 100 000 անգամ: Թռիչք, որն անհնարին է պատկերացնել ավանդական եղանակով զարգացման համար, և որը գերազանցում է վերջին 20 տարիներին հաշվիչ տեխնիկայում արձանագրված առաջընթացը:
Հաջորդը. Google Books կորպուսում առկա են 7 լեզուներ: Ինչպես և պետք էր սպասել, ամենածավալունը անգլերենի կորպուսն է՝ մոտ 361 մլրդ բառօգտագործման միավոր (67%): Ընդ որում, կորպուսը տարբերակում է ամերիկյան անգլերենը բրիտանականից: Կորպուսում առկա են նաև իսպաներենն ու ֆրանսերենը՝ մոտ 45 մլրդ միավոր յուրաքանչյուրը, գերմաներենը՝ 37 մլրդ միավոր, ռուսերենը՝ 35 մլրդ, չինարենը՝ 13 մլրդ և եբրայերենը՝ 2 մլրդ (տես՛ լուսամուտում): Վերջինիս առկայությունն այստեղ չափազանց ուշագրավ է, մանավանդ որ այստեղ բացակայում է ոչ միայն համեստ հայերենը, այլև, օրինակ, հինդին, բենգալերենը, տամիլերենը, ճապոներենը կամ արաբերենը, որոնցով առկա տպագիր գրականությունը հսկայական է: Այս երևույթի մակերեսային բացատրությունը դժվար չէ գտնել [13]։ Հեղինակային թիմի 13 անդամից առնվազն երեքը հրեա է: Իսկ ավելի խորքային բացատրությունների փնտրտուքը մեզ հեռուն կտանի:
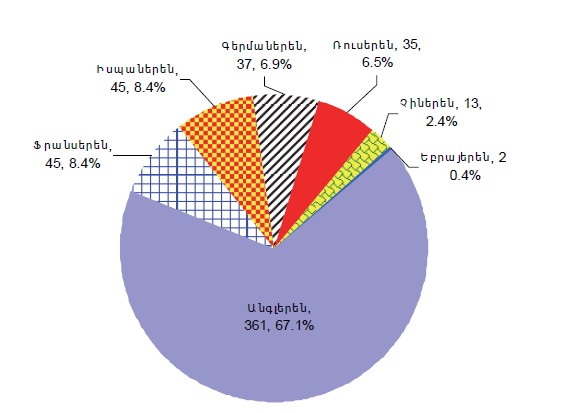
Փաստենք միայն հետևյալը, աշխարհում առկա մոտ 7.0 հազար լեզուներից Google Books լեզվական կորպուսում տեղ է գտել միայն 7-ը (0.1%): Այս երևույթը, իր խորքային պատճառներից մեկով, համարժեք է նրան, որ, օրինակ, XX դարասկզբին աշխարհում ինքնաթիռներ էր արտադրում ավելի քան երկու տասնյակ երկիր: XX դարի կեսերին ավիացիոն ռեակտիվ շարժիչներ ունակ էր արտադրել արդեն միայն 7-ը: Իսկ այսօր լայնաֆյուզելյաժ ինքնաթիռներ կարող է արտադրել միայն ԱՄՆ-ը։ Եվ Եվրամիությունը, այն էլ՝ մասամբ13։
Google Books կորպուսի մյուս կարևոր ձեռքբերումը Google N-grams հասկացության ներմուծումն է: Բանն այն է, որ ավանդական հաճախակիության բառարանները և լեզվական կորպուսները կազմված էին հիմնականում մեկ միավոր բառից (իմաստային նիշից): Սա հավասարազոր է Google Books կորպուսների 1-gram հասկացությանը: Այն է՝ մեկ առանձին բառ, օրինակ՝ «if» (եթե) բառը: Կամ մեկ իմաստային նիշ, օրինակ՝ «1915»: Սակայն Google Books կորպուսներում դիտարկվում են նաև 2-gram, 3-gram, 4-gram և 5-gram հասկացությունները, ինչը համարժեք է 2, 3, 4 և 5 բառից կազմված բառակապակցություններին: Այսպես, Google Books ռուսերեն կորպուսում առանձին-առանձին դիտարկվում են և՛ «СССР»-ը (1-gram) և՛ «Союз Советских Социалистических Республик» բառակապակցությունը (4-gram):
Հաջորդ կարևորագույն ձեռքբերումն այն է, որ Google Books կորպուսներն ըստ էության ներկայացնում են ավանդական լեզվական կորպուսների, լավ դասակարգված տվյալների շտեմարանների, որոնումներ, զտումներ ու ենթադասակարգումներ կատարելու և արդյունքներն արտապատկերելու գործիքների մի համալիր միասնություն: Այս ամենը կոչվեց Google N-grams գործիք14։ Սա արդեն ոչ միայն քանակական, այլև որակական առաջխաղացում է: Քանի որ մարդկային կուլտուրայի պատմության մեջ առաջին անգամ հնարավորություն ստեղծվեց դիտարկել առանձին բառի կամ բառակապակցությունների հաճախակիության դինամիկան՝ նախկինում նախադեպը չունեցող ռեպրեզենտատիվությամբ և մոտ 2 դար տևողությամբ ժամանակային տիրույթում: Բացի դա, գործիքը հնարավորություն է տալիս ակնառու պատկերել այս դինամիկան հաճախակիության բաշխման գրաֆիկների տեսքով:
Վերջապես, Google N-grams գործիքը հանրայնացվեց նախկինում նախադեպը չունեցող մակարդակով: Սկսած 2011թ. հունվարից՝, յուրաքանչյուր ոք աշխարհում, ով ունի հաշվիչ և միացում համացանցին, կարող է օգտվել դրանից15։ Ավելին, նա կարող է ներբեռնել Google Books լեզվական բոլոր 7 կորպուսները կամ նրանցից յուրաքանչյուրում առկա Google N-grams բոլոր հինգ ենթաբազմությունները: Այլ հարց է, թե ինչ ենք անելու, ինչ ենք ունակ անել՝ ներբեռնելով, օրինակ, 361 մլրդ միավոր անգլերեն Google 1-grams բազմությունը: Առավել ևս, որ օգտատերերի համար հասանելի են միայն զուտ բազմությունները, բայց ոչ դրանց թագերը, ներքին կապերը և մետադատան: Այստեղ մենք նորից հանդիպում ենք արդեն ծանոթ իրադրությանը. մեզ (անսպասելիորեն) հասանելի է դառնում տվյալների հսկայական բազմություն՝ լինեն ԱՄՆ Պետդեպի մոտ կես մլն գաղտնի հաղորդագրությունները, օֆշորային գոտիներում միլիոնավոր գործարքների մասին տվյալները, FOIA շրջանակներում գաղտնազերծված տասնյակ միլիոնավոր էջ փաստաթղթերը, թե Google N-grams միլիարդավոր բառերի բազմությունը: Ի՞նչ անել դրանց հետ, որքանո՞վ են հնարավոր դրանց իմաստալից և արդյունավետ յուրացումն ու վերլուծությունը՝ ամբողջությամբ պայմանավորված է մեր պակերացումներով, մղումներով, հնարավորություններով և ունակություններով:
Google N-grams գործիքի հանրայնացումը նպաստեց բառօգտագործման նկատմամբ հետաքրքրության աննախադեպ աճին: Անցած 6 տարիների ընթացքում հրատարակվեցին հարյուրավոր ուսումնասիրություններ՝ նվիրված լեզվի էվոլյուցիային և բառօգտագործման առանձնահատկություններին և հիմնված քանակական գնահատականների վրա [13]։ Հեղինակները խոսում են նույնիսկ գիտության մի նոր ճյուղի՝ կուլտուրոմիկայի (Culturomics) մասին: [13]-ի հեղինակներն այն բնութագրում են իբրև հաշվիչ բառագիտության (computational lexicology) մի տարատեսակ, որը թվայնացված տեքստերի քանակական վերլուծության հիման վրա ուսումնասիրում է մարդու վարքը, մարդկային կուլտուրայի զարգացման միտումներն ու օրինաչափությունները: Ստորև ներկայացնենք դրա օրինակները՝ վերցված թե՛ [14]-ից, թե՛ պատրաստված հատուկ սույն հոդվածի համար:
Այստեղ անդրադառնանք կուլտուրոմիկայի ծիրում 2011թ. հրապարակված ևս մի աշխատության: Այն վերնագրված է «Կուլտուրոմիկա - 2.0. մարդկանց մեծ խմբերի վարքի կանխատեսում՝ հիմնված գլոբալ լուրերի տոնայնության և տարածական տեղորոշման վրա» [14]: Եվ ի մի է բերում ԱՄՆ մի շարք համալսարաններում ու գիտական կենտրոններում գլոբալ լուրերի հոսքի տարիներ տևող կոնտենտ-վերլուծությունների արդյունքները: Որպես աղբյուր [14]-ում վերցված են ԱՄՆ Open Source Center16 և բրիտանական Summary of World Broadcasts (SWB)17 կազմակերպությունների կողմից կանոնավոր հավաքված գլոբալ օրական լուրերի շտեմարանները, ինչպես նաև սոցցանցերից հավաքագրված տեղեկատվությունը: Կոնտենտ-վերլուծության համար [14]-ում կիրառվել է տեքստերի «լեռնահանման» (text mining) երկու գործիք. «զգացմունքների լեռնահանում» (sentiment mining, 2004)18 և տեքստերի տեղավայրային կոդավորում (full–text geocoding, 2007)19:
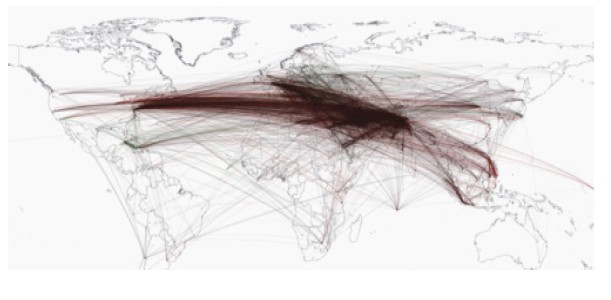
Նկար 2. «Bin Laden» բառակապակցության տոնայնա-տեղորոշման (geocoded tone) գլոբալ գրաֆը՝ կառուցված 1979թ. հունվար - 2011թ. ապրիլ ժամանակահատվածի նորությունների բազմության համար [14]:
Ստացված արդյունքները, ի շարս այլոց, հնարավորություն տվեցին նկարագրել «Արաբական գարնան» իրադարձությունների դինամիկան, դրանց ուժգնությունը Թունիսում և Եգիպտոսում (ինչը հանգեցրեց այստեղ ռեժիմների փոփոխության) և թուլությունը Սաուդյան Արաբիայում (իշխանափոխության ցածր հավանականություն), ինչպես նաև տեղորոշել առանձին անհատների գտնվելու վայրը: Մասնավորապես, 1979թ. հունվար - 2011թ. ապրիլ ժամանակահատվածում SWB բազմության հիման վրա կառուցված օրական լուրերի տոնայնա-տեղորոշման (geocoded tone) գլոբալ գրաֆը (տես՛ Նկ. 2) թույլ տվեց տեղորոշել Օսամա բին Լադենի գտնվելու հավանական վայրը՝ 200 կմ շառավղով տարածք Հյուսիսային Պակիստանում, որը ներառում էր Աբբոթաբադ քաղաքը: 2011թ. մայիսին այստեղ հայտնաբերվեց ու ոչնչացվեց O. բին Լադենը:
5. Մենք և դեկտեմբերյան մեծ հեղափոխությունը
Ինչպիսի՞ն է վիճակը Հայաստանում «բառերի տիեզերքի» ուսումնասիրության տեսանկյունից: Բերենք որոշ թվեր: Համաձայն ՀՀ Ազգային գրադարանի տվյալների [16], Հակոբ Մեղապարտից՝ 1512 թվականից մինչև մեր օրերը ողջ աշխարհում տպագրվել է մոտ 126 հազ. անուն հայերեն գիրք: Ըստ նույն աղբյուրի, «առայժմ թվայնացվել է դրա 7%-ը՝ 6700 անուն գիրք»: Առաջին հայացքից սա կարծես թե վատ չէ: Տոկոսային առումով նույնիսկ ավելին է, քան Google N-grams-ի 4% ցուցանիշը: Բացի այդ, համաձայն նույն աղբյուրի, «սկսած «Ազդարարի» տպագրությունից, հայ մամուլն աշխարհում պարունակում է 5784 անուն օրաթերթ, ամսագիր և պարբերական: 2016թ. դրությամբ թվայնացվել է մոտ 2 մլն էջ հայկական մամուլ» [15]: Թե դեռ որքան է մնացել թվայնացնել՝ աղբյուրը չի նշում: Բայց դա չէ կարևորը:
Կարևորն այն է, որ մեզանում «թվայնացում» եզրն օգտագործվում է ոչ համարժեք կերպով: Դրա տակ հաճախ նկատի ունեն պարզապես տեքստերի հասարակ սքանավորում:20 Սքանավորման արդյունքում տեքստը, այո՛, կարող է հասանելի դառնալ համացանցում, ինչն ինքնին շատ լավ է: Բայց այն հասանելի է ոչ որպես «թվայնացված», առավել ևս՝ դասակարգված բազմություն, այլ որպես պարզունակ նկար: Հետևաբար, այն պիտանի չէ լեզվական, լեզվահոգեբանական, բառօգտագործման հաճախակիության, լեզվական էվոլյուցիայի և նմանատիպ այլ հետազոտությունների կամ լեզվական ազգային կորպուսի ստեղծման համար: Իրական թվայնացումը ենթադրում է տեքստի յուրաքանչյուր միավորի (տառ, մասնիկ, կետադրական նշան, բառ, բառակապակցություն) առանձին-առանձին ճանաչում և կոդավորում, թվայնացված տվյալների թագերի ստեղծում (բառի քերականական, աղբյուրաբանական, ժամանակագրական, տոնայնության, տեղորոշման և այլ հատկանիշներ), ներքին կապերի հաստատում, թվայնացված տվյալների դասակարգում և այլն: Սա է տեքստերի թվայնացման էությունը և դրա ամենաարժեքավոր21 մասը: Հայկական համացանցի անգամ թռուցիկ ուսումնասիրությունը վկայում է, որ [15] աղբյուրն իրականում նկատի ունի գրքերի և մամուլի սքանավորում, այլ ոչ թե թվայնացում: Այսօր թվայնացված է հայերեն գրքերի և մամուլի միայն չնչին տոկոսը:
Այնուամենայնիվ, կան և լավատեսության նշույլներ: Այսպես, 2010թ. դեկտեմբերի 19-ին՝ Google N-grams գործիքի թողարկմանը համընթաց, հայկական համացանցում նորամուտը նշեց «Հայկական գիտական համագործակցություն» կայքը22, որի հիմնադիրները երեք երիտասարդներ էին (Ա.Մարտիրոսյան, Խ.Հարությունյան, Ս.Հովհաննիսյան): Այստեղ առկա են իրոք թվայնացված գրքեր և բառարաններ: Մյուս կարևոր ձեռքբերումը 2005-ից գործող «ՆԱԻՐԻ» հայերեն էլեկտրոնային բառարանների առցանց գրադարանն է (հիմնադիր՝ Ս.Ուրիշեան, ԱՄՆ)23, ուր առկա են (մասնակիորեն) թվայնացված արևմտահայերեն բառարաններ: Կարևոր է նաև այն, որ ՀՀ Ազգային գրադարանը24 համագործակցում է այս և այլ նմանատիպ նախաձեռնությունների հետ: Վերջապես, հուսադրող է նաև հայալեզու WEB-ի համեմատաբար բարձր հագեցածությունը, գոնե՝ քանակական առումով: Դա հատկապես վերաբերում է հայալեզու Wikipedia-ին25։
Սակայն այս ամենը բավարար չի կարելի համարել: Այսօր մենք ականատեսն ենք աշխարհում ընթացող երկու կարևորագույն, որոշ առումներով՝ հակադրիր միտումների: Մի կողմից՝ գիտատեխնոլոգիական սրընթաց զարգացում, տվյալների մեծ շտեմարանների ստեղծում (տե՛ս հաջորդ բաժնում), հեռահաղորդակցության միջոցների զարգացում և դրանց հանրայնացում: Մյուս կողմից՝ հիմնարար նշանակության տեխնոլոգիաների, գիտելիքների ու հմտությունների կենտրոնացում քիչ թվով պետությունների ու ֆինանսատեխնոլոգիական խմբերի ձեռքում, դրանց օտարում մարդկության և երկրների մեծամասնությունից: Ավելին, գլոբալ առումով անկում են ապրում հանրային կրթական համակարգը, գիտական մտածելակերպը, քննադատական մտածողությունը: Հակադիր այս միտումներն օրեցօր դառնում են ավելի հուժկու՝ վկայելով նոր մարտահրավերների գալուստը:
* * *
Այսօր, երբ այլևս գոյություն չունի աշխարհի երկբևեռ համակարգը, ուսանելի է կարդալ Ու.Օրթմանի 1978-ին արած դառը գանգատներն առ այն, որ Քայդինգի հսկայական արխիվը պահպանվել էր միայն ԳԴՀ-ում [16]: Իսկ պահպանվե՞լ է արդյոք ՀԽՍՀ օրոք ստեղծված Ա.Մ. Մարջանյանի կամ Բ.Կ. Ղազարյանի բառարանների արխիվը, թվայնացվե՞լ է արդոք [11] բառարանը: Կազմվե՞լ է արդյոք հայոց լեզվի հաճախակիության կորպուսը, համեմատվե՞լ է արդյոք այն [11]-ի հետ: Չէ՞ որ այսպիսի համեմատական վերլուծությունը չափազանց ուսանելի կլիներ: Եվ ընդհանրապես, գիտե՞նք արդյոք, թե ինչ երկրում ենք ապրում: Ի՞նչ սոցիալ-հոգեբանական, սոցիալ-տնտեսական պրոցեսներ են ընթանում մեզանում այսօր: Ի՞նչ ապագա են ձևավորելու դրանք վաղը: Արդյո՞ք մենք պատկերացում ունենք, թե ինչ պրոցեսներ են ընթանում արդի հայերենում, հայերեն լեզվամտածողությունում, հայերեն եզրերի ստեղծման ու կիրառման գործում:
Չէ՞ որ այսպիսի իմացությունը՝ հիմնված քանակական գնահատականների վրա, վեր կհաներ արդի հայերենի դինամիկայի կարևոր առանձնահատկությունները և օրինաչափությունները: Եվ գուցե հնարավոր լիներ վաղօրոք, թվերով ու քանակական գնահատականներով ցույց տալ Հայաստանում «հասարակական պայմանագրի» խախտման հասունացումը 2012-15թթ.: Կամ, վերլուծելով ադրբեջանական և թուրքական լուրերի տեքստերը, իրականացնելով դրանց «զգացմունքային լեռնահանումն» ու տոնային-տեղորոշումը, գնահատել հակամարտության գոտում ակտիվ գործողությունների վերսկսման վտանգը 2016-ին: Կամ քանակական գնահատականների հիման վրա բացահայտել, թե ինչու, ինչպես և ինչ տրամաբանությամբ XX դարում Ստանիսլավ Լեմի իմաստուն պատմաբան (և կոմունիստ) Տեր հորը, քաջարի աստղանավիգատոր Տեր-Ակոնյանին, ականավոր կենսաբան Չաքաջանյանին26, Ստրուգացկի եղբայրների անվախ տիեզերագնաց-փորձարկու Աշոտ Պետրոսյանին, գծային երջանկության բաժնի ավագ գիտաշխատող Էդիկ Ամպերյանին27 XXI դարում փոխարինելու եկավ Վիկտոր Պելևինի Էդիկ Դեբիրսյանը, նույն ինքը՝ Սաշա Բլոն28։ Ու միգուցե նոր լույս սփռվեր այն ահասարսուռ փաստի վրա, որ երևակայական «Դատապարտված քաղաքում» շարքային Թևոսյանին գիշերով քնի մեջ մորթած Պերմյակին29 մեր, Ա.Ազիմովի բառերով՝ «ընթացիկ» իրականությունում30 փոխարինելու եկավ տխրահռչակ Պերմյակովը:
Արդյո՞ք մենք ունակ ենք բանն ու բառը դարձնել գործ: Իսկ գործը՝ բառ ու եզր:
1 Բազմանշանակ զուգադիպությամբ իրադրությունը գրեթե նույնն է նաև Արևելյան կիսագնդում: Չինական աշխարհում կցիտվեր Դաո Դե Ցզինի 81-րդ ջանը՝ Դաո հիերոգլիֆի եռակի օգտագործումով: Հնդկաստանում՝ Չխանդոգյա ուպանիշադի առաջին տողերը՝ Աում վանկի եռակի ընկալմամբ: Ճիշտ ինչպես Յովհաննէսի, ավելի ճիշտ՝ Հերակլիտեսի լոգոսի պարագայում:
2 Անգլերեն Word-ը մեզ համար այլևս ոչ միայն բառ է նշանակում, այլև բոլորիս հայտնի ծրագիր: Ու դեռ հարց է, թե ոչ այնքան հեռու ապագայում այն ինչ կնշանակի մեր թոռների համար՝ առաջին հերթին:
3 Մեկ այլ հետաքրքիր օրինակ. 1956-ին ԽՍՀՄ-ից վերադարձած գերմանացի դարբին ռազմագերին իր արևմտյան քննիչներին էր հաղորդել տեղացիների մոտ ընդունված «Это не Томск, а Атомск» բառակատակը: Դա օգնեց ներառել այս տեղավայրը U-2 լրտես օդանավի թռիչքային առաջադրանքում և 1957թ. ամռան վերջին տեղորոշել ԽՍՀՄ «Ատոմային արշիպելագի» ուրանի հարստացման հույժ գաղտնի արդյունաբերական օբյեկտները [2]:
4 Եթե, իհարկե, այն, Բորխեսի մղձավանջային «Ավազե գրքի» (1975թ) նման, չունի անվերջ թվով էջեր, որոնք շարունակ շերտվում են գրքի կազմից:
5 Օրինակ՝ հողմահոսանքի արագության հաճախակիության բաշխումը [5]:
6 ԽՍՀՄ հայտնի լրտես Ռ.Աբելի (Վ.Ֆիշերի) անձնական շիֆրի «СНЕГОПА(д)» գաղտնաբառի ընդամենը 7 տառերը փակում են սովորական ռուսերենում օգտագործվող տառերի հաճախակիության մոտ 40%-ը: Այս հանգամանքը հնարավորություն էր տալիս նույնքան չափով կրճատել թե՛ գաղտնագրված տեքստի երկարությունը, թե՛ դրա հաղորդման տևողությունը, ինչը գրեթե անհնար էր դարձնում հաղորդչի տեղորոշումը: Աբելի ձերբակալումը 1957-ին հնարավոր դարձավ միայն կապավորի մատնության հետևանքով: Նրանից էլ հայտնի դարձան Աբելի անձնական շիֆրի մասին բերված մանրամասները [7]:
7 Հայտնի մաթեմատիկոս Հ.Վեյլի հետ ստիպված ենք անել հետևյալ գանգատը: «Հաճախություն» (frequency, частота) բառը շատ լեզուներում ունի երկու միանգամայն տարբեր իմաստ. 1) Տատանողական, հետևաբար՝ կանոնակարգված, պրոցեսների հատկանիշ (չափման միավորը՝ տատանում վարկյանում); 2) վիճակագրա-ստոխաստիկ հատկանիշ, այսինքն՝ որևէ, պարտադիր չէ կանոնակարգված, պրոցեսում կամ բազմությունում որևէ առանձնյակի (specimen) հայտնվելու քանակական ցուցանիշ (%): Առաջին իմաստով հայերենում ընդունված է «հաճախություն» եզրը: Բայց այն սովորաբար, և միանգամայն անհիմն, դառնում է «հաճախականություն» (14 տառ): Ուստի, ամենայն հարգանքով [11] բառարանի հանդեպ, մենք այստեղ խոսում ենք բառի օգտագործման հաճախակիության, այլ ոչ թե ցանկալի՝ հաճախության կամ արհեստածին հաճախականության մասին:
8 Աշխարհի մեկ օրվա ստատիկ կտրվածք ստանալու, այն ֆիքսելու և պատկերելու յուրօրինակ ձեռնարկում էր «Աշխարհի մեկ օրը» գրքերի հրատարակումը ԽՍՀՄ-ում: Այն Մ.Գորկու 1934թ. նախաձեռնությունն էր: Առաջին այսպիսի գիրքը հրատարակվեց 1937-ին՝ Գորկու սպանությունից մեկ տարի անց: Այն պատկերում էր ողջ աշխարհում 1935թ. սեպտեմբերի 27-ին տեղի ունեցածը՝ եղանակից մինչև պատերազմներ, այդ օրը մարդկանց կողմից ուղարկված հեռագրերից մինչև քաղաքական իրադարձություններ: Գիրքը կրում էր վառ արտահայտված քարոզչական բնույթ: Հմմտ. Ս.Լեմի «Մարդկության մեկ րոպեն» սքանչելի ապոկրիֆի հետ (Jedna Minuta, 1984):
9 Եթե այն լիներ, ապա տեղ կզբաղեցներ «геноcce» և «генштаб» բառերի միջև ([9, стр. 135]):
10 Չափազանց կիրառելի անգլերեն tag եզրը ռուսերեն մասնագիտական գրականությունում առանց որևէ բարդույթի բերվում է ֆոնետիկ թարգմանությամբ՝ «тег»: Հայերեն մասնագիտական գրականությունը առաջարկում է «հատկորոշիչ» (10 տառ) կամ «գլխաբառ» (7 տառ) բառերը: Այնինչ, իրանա-հայկական «թագ» բառը ([1, հ. 2, էջ 135]) ոչ միայն tag-ի ֆոնետիկ պատկերն է, այլև tag եզրի ճշգրիտ համարժեքը: Ի վերջո, չէ՞ որ թագադրումը՝ դա հատկորոշում է, պիտակավորում՝ par excellence:
11 Հետևելով Էզրա Փաունդի պատվիրանին՝ մենք Culture բառի (և հասկացության) համար օգտագործում ենք «կուլտուրա» եզրը, խուսափելով «մշակույթ» ոչ համարժեք և ապակողմնորոշող բառի օգտագործումից: Հոդվածում չի օգտագործվում նաև «համակարգիչ» ապակողմնորոշող բառը: Համակարգում են միայն կամքը, մարդը կամ գաղափարը, բայց ոչ կոմպյուտերը: Փոխարենը կիրառվում է միանգամայն համարժեք «հաշվիչ» եզրը:
12 Ուշագրավ զուգադիպությամբ այդպիսին է նաև համացանցում «մութ ցանցի» (dark web) մասնաբաժինը, որը տեսանելի չէ սովորական օգտատիրոջ որոնողական համակարգերի համար:
13 Բրեքսիթից հետո բրիտանական «Ռոլսռոյս» ավիացիոն շարժիչները ֆորմալ առումով դուրս են ԵՄ տիրույթից: ՌԴ-ն լքեց այս ցանկը վաղ 90-ականներին:
14 https://books.google.com/ngrams
15 http://storage.googleapis.com/books/ngrams/books/datasetsv2.html
16 Նախկինում՝ Foreign Broadcast Monitoring Service. հիմնվել է 1941թ. փետրվարին՝ ԱՄՆ Հեռահաղորդակցության դաշնային խորհրդի կազմում: 1947-ից այն վերանվանվում է Foreign Broadcast Information Service ու փոխանցվում ԱՄՆ ԿՀՎ-ին՝ որպես հետախուզական բաց աղբյուրների հավաքագրման և վերլուծության կենտրոն:
17 Հիմնվել է 1939թ. ամռանը՝ Բրիտանական հեռարձակման կորպորացիայի (BBC) կազմում: 1947-ից կազմում է գլոբալ լուրերի օրական հաշվետվությունները՝ Summary of World Broadcasts:
18 Հիմնված է տեքստերում զգացմունք արտահայտող բառերի հաճախակիության վերլուծության վրա:
19 Հիմնված է տեքստերում տեղանունների հաճախակիության վերլուծության վրա:
20 Եզրերի այսչափ անբռնազբոս, հետևանքներով՝ կործանարար օգտագործումը, ցավոք, եզակի երևույթ չէ հայերենում: Հիշենք միայն «բարձր տեխնոլոգիաներ» եզրը, որը մեզանում նույնացվում է հաշվիչից օգտվելու կամ ինտերնետին միացված լինելու, կամ լեգո կոնստրուկտորից այսպես ասած «ռոբոտներ» հավաքելու հետ:
21 Զուր չէ, որ անգլերեն classifiy բառը նշանակում է և՛ դասակարգել, և՛ գաղտնագրել: Իսկ գաղտնագրում են սովորաբար ամենաարժեքավոր, հիմնարար կարևորության բաները:
22 Armenian Scientific Cooperation. http://armscoop.com
24 http://www.nla.am/arm/?q=hy
25 Այս հարցին կանդրադառնանք «Հայալեզու WEB-ը որպես կորպուս. լեզվական ու բանակային» հոդվածում, «Նորվանք» ԳԿՀ «Գլոբուս» ամսագրի առաջիկա համարում:
26 Ստանիսլավ Լեմ, «Obłok Magellana», 1954թ., «Магеланово облоко», 1960թ.: Ս.Լեմի և հայության «միստիկ» կապի մասին տես՛ Генетика E.Сoli и Эрунтика Станислава Лема, «Мост», 24 Апрель, 2014:
27 Ստրուգացկի եղբայրներ, «Страна багровых туч», 1959թ., «Понедельник начинается в субботу», 1965թ.:
28 Վիկտոր Պելևին, Generation «П», 1999թ.:
29 Ստրուգացկի եղբայրներ, «Град обреченный», 1972թ., հրատարակված է 1988-89թթ.:
30 Ա.Ազիմով, «Հավերժության վերջը» (End of Eternity, 1955թ.):
(Շարունակելի)
Նոյեմբեր-դեկտեմբեր, 2016թ.
Աղբյուրներ և գրականություն
1. Աճառյան Հր., Հայերեն արմատական բառարան, Երևանի համալսարանի հրատարակչություն, Երևան, 1971-79թթ.։ Մեր ապագան` NIC աչքերով, «Նորավանք» ԳԿՀ, «21-րդ ԴԱՐ», թիվ 2 (24), 2009թ., էջ 26-63, http://noravank.am/arm/issues/detail.php?ELEMENT_ID=5869 ։
2. Lowenhaupt, Henry S., Mission to Birch Woods. Studies in Intelligence. Vol.12.4-1-12, Fall 1968. SECRET, NOFORN. Declassified and Released under FOIA, Sept 1994.
3. Kaeding, F.W., Häufigkeitswörterbuch der deutschen Sprache. Festgestellt durch einen Arbeitsausschuß der deutschen Stenographie-Systeme. Vol 1, Wort- und Silbenzählungen. Vol 2, Buchstabenzählungen. Selbstverlag des Herausgebers, Steglitz bei Berlin: 1897, 1898.
4. Бойков, В.В., Жукова, Н.А., Романова, Л.А., Распределение длины слов в русских, английских и немецких текстах, Мир лингвистики и коммуникации, т. 1, Nо 1, 2005.
5. Խաչատրյան Վ.Ս., Մարջանյան Ա.Հ., Արդի հողմաէներգետիկա, Երևան, 1987թ։
6. Josselson, H. H., The Russian Word Count and Frequency Analysis of Gramatical Categories of Standard Literary Russian. Detroit, Wane Univ. Press, 1953.
7. Kahn, David, Number One From Moscow. Studies in Intelligence. Vоl 5.4-A15-A28. Fall 1961. SECRET, NOFORN. Declassified and Released under FOIA Sept, 1993.
8. Штейнфельдт Э.А., Частотный словарь современного русского литературного языка, Таллин, 1963.
9. Частотный словарь русского ЯЗЫКА, под ред. Л.Н. Засориной, М., “Русский язык”, 1977.
10. Ղազարյան Բ.Կ., Հայոց լեզվի հաճախականության թեմատիկ բառարանի կազմումը, Պատմաբանասիրական հանդես, 1968թ, № 4, էջ 225-232։
11. Ղազարյան Բ.Կ., Ժամանակակից հայոց լեզվի հաճախականության բառարան, Երևան, Հայկական ՍՍՀ ԳԱ, 1982։
12. Մարջանյան Ա.Հ., Էներգետիկա և աշխարհաքաղաքականություն, «Նորավանք» ԳԿՀ, «21-րդ ԴԱՐ», թիվ 1 (1), 2003, http://cyberleninka.ru/article/n/ehnergetik%D0%B0-i-geopolitik%D0%B0-66։
13. Michel, J-B., et all, Quantitative Analysis of Culture Using Millions of Digitized Books. Science, Vol, 331, 14 Jan 2011, pp. 176-182.
14. Leetaru, K.H., Culturomics 2.0: Forecasting Large-Scale Human Behavior Using Global News Media Tone In Time And Space”. First Monday, No 16 (9), 5 September 2011.
15. Ազգային գրադարանի տնօրենն ամփոփեց ավարտվող տարվա արդյունքները, Ազատություն ՌԿ, 20/12/2016, http://www.azatutyun.am/a/28186942.html։
16. Ortmann, W.D., Hochfrequente deutsche Wortformen IV. 7695/9566 Wortformen der KAEDING-Zählung, rechnersortiert nach Textsorten-Distribution. Herausgegeben vom Goethe-Institut, Arbeitsstelle für wissenschaftliche Didaktik, Projekt Phonothek. Goethe-Institut, München, 1978.
դեպի ետ
Հեղինակի այլ նյութեր
- «ՀԱՅԱՍՏԱՆՆ ԻՐ ՄՏԱՀՈԳՈՒԹՅՈՒՆԸ ՊԵՏՔ Է ՀԱՅՏՆԻ ԱԴՐԲԵՋԱՆՈՒՄ ԱԷԿ-Ի ԿԱՌՈՒՑՄԱՆ ԱՌՆՉՈՒԹՅԱՄԲ». ՓՈՐՁԱԳԵՏ[17.12.2018]
- ՀՈՒՄ ՆԱՎԹԻ ԱՐԴՅՈՒՆԱՀԱՆՈՒՄՆ ԻՍՐԱՅԵԼՈՒՄ[05.11.2018]
- ՇՓՄԱՆ ԳԻԾ–ԱՐԱ ՄԱՐՋԱՆՅԱՆ (05.10.18)[09.10.2018]
- ՀԱՅԱՍՏԱՆ – ՌՈՒՍԱՍՏԱՆ ՌԱԶՄԱՔԱՂԱՔԱԿԱՆ ԴԱՇԻՆՔԸ ԱՐԴԻ ՓՈՒԼՈՒՄ. ԻՐՈՂՈՒԹՅՈՒՆՆԵՐ, ՎՏԱՆԳՆԵՐ, ՀԵՌԱՆԿԱՐՆԵՐ[07.08.2018]
- ԳԼՈԲԱԼ ՏԱՐԱԾԱՇՐՋԱՆՆԵՐ, ՍԵՐՆԴԱՅԻՆ ԱԼԻՔՆԵՐ ԵՎ ՊԱՏՄԱԿԱՆ ՔԱՂԱՔԱԿԱՆՈՒԹՅՈՒՆ[19.07.2018]
- ՀԱՅԱՍՏԱՆ-ՌՈՒՍԱՍՏԱՆ ՌԱԶՄԱՔԱՂԱՔԱԿԱՆ ԴԱՇԻՆՔՆ ԱՐԴԻ ՓՈՒԼՈՒՄ. ԻՐՈՂՈՒԹՅՈՒՆՆԵՐ, ՎՏԱՆԳՆԵՐ, ՀԵՌԱՆԿԱՐՆԵՐ[09.07.2018]
- ԻՍՐԱՅԵԼԸ ԱԴՐԲԵՋԱՆԻՆ ԿՕԳՏԱԳՈՐԾԻ ԻՐԱՆԻՆ ՀԱՐՎԱԾԵԼՈՒ ՀԱՄԱՐ (տեսանյութ)[16.05.2018]
- ԻՆՏԵՐՆԵՏ ՕԳՏԱՏԵՐԵՐԻ ԹԻՎԸ ՀԱՅԱՍՏԱՆՈՒՄ ԵՎ ՏԱՐԱԾԱՇՐՋԱՆՈՒՄ[08.05.2018]
- ԱԴՐԲԵՋԱՆԻ ԿՈՍՄԻԿԱԿԱՆ ԾՐԱԳՐԻ ՀԵՏԱԽՈՒԶԱ-ՀԵՌԱԶՆՆՄԱՆ ԲԱՂԱԴՐԻՉԸ[09.04.2018]
- ՀԱՐԱՎԱՅԻՆ ԿՈՎԿԱՍԻ «ԲԱՆԱԼԻՆ» ՆԱԽԻՋԵՎԱՆՈՒՄ Է. Ա.ՄԱՐՋԱՆՅԱՆ[26.02.2018]
- ԱԴՐԲԵՋԱՆԻ ՏԻԵԶԵՐԱԿԱՆ ՏԵԽՆՈԼՈԳԻԱԿԱՆ ՍԵԳՄԵՆՏԸ[19.02.2018]